MySQL 总结(二)
MySQL 注意的点:
写代码的时候突然觉得自己 SQL 方面有点弱,于是有了这篇文章
为什么 where 不能用字段别名。因为 mysql 执行顺序:
1 | -- 错误: |
limit 使用方法
1 | -- 这条语句意思是 从第 51 条数据(包括 51) 开始数,数 10 条数据出来 |
从 sql 优化来说,多表查询的字段最好都指明表名。减少 sql 找字段的时间。当然如果有同样的字段那肯定得指定的。
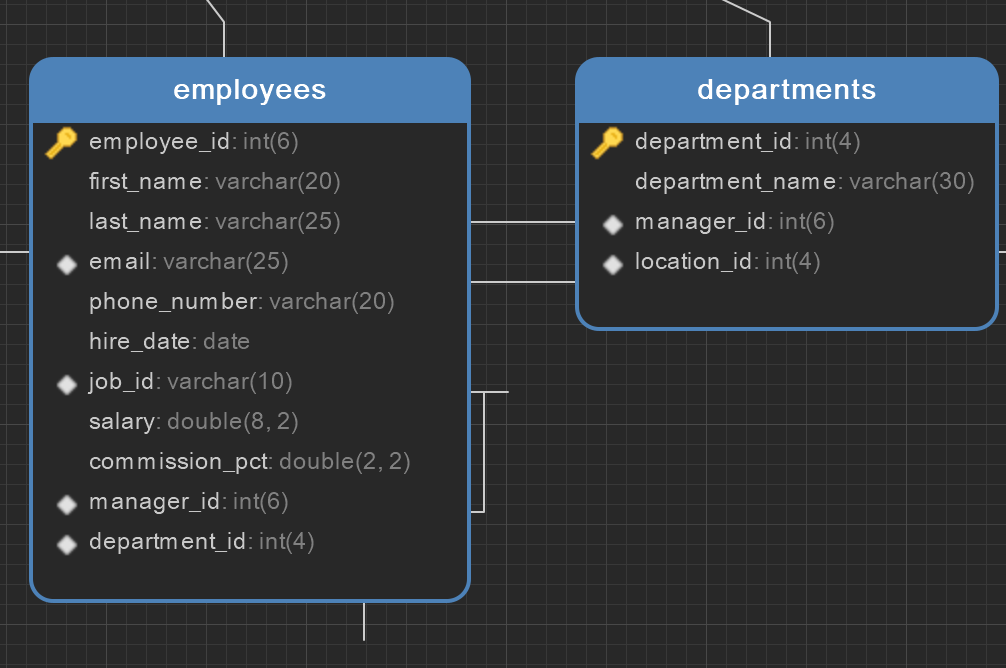
E-R 图
1 | -- 正确: |
如果给表起了别名,在 select 或者 where 中使用表名的话,必须用别名,否则报错。因为 mysql 的执行顺序,表的别名会覆盖表名
1 | -- 正确 |
UNION 操作会返回两个查询结果的并集,会去除相同的记录,而 UNION ALL 不会去重,可以不去重就不去重的写法,去重是 mysql 去重的,所以 UNION ALL 效率高。
COUNT() 是计算不包括 null 的个数
酷COUNT(*),COUNT(1),COUNT(字段)哪个效率更高?
如果是 MyISAM 存储引擎,三者效率都一样,因为这个引擎有一个字段专门存多少行的。
如果是 InnoDB 存储引擎,则效率:COUNT(1)=COUNT(*)>COUNT(字段), 因为这个引擎会自动找 len 最短的去 count, 指定了字段没法优化。
这是结论:GROUP BY 语句中,select 字段中只能存在除聚合函数的 GROUP BY 字段。否则查出来的数据没有意义。
1 | 正确 |
HAVING 必须在 GROUP BY 的后面,使用 HAVING 的前提是有 GROUP BY
where 和 having 效率区别,以及使用区别
没有聚合函数的情况下最好用 where 先判断条件。然后再分组再用 having 去操作条件,不然会 把没用的数据也给分组,浪费性能。
where 后面不能跟聚合函数,因为你就一组你没分组聚合按照条件没有意义啊。但是 HAVING 可以因为你分了很多个组所以就可以筛选。
mysql 执行顺序
1 | SELECT FROM 这里后执行 |
GROUP BY 和 HAVING 可以使用 select 字段的别名,这是 MySQL 特殊的,按道理来说也就是执行顺序来说是不可以使用别名的。这是 MySQL 为了偷懒,我认为。
MYSQL 中不能聚合套聚合,这是他的缺陷,但是 ORACLE 可以
子查询和自连接相对来说,自连接好一些,因为子查询是通过未知表进行查询的条件判断,而自连接是通过已知的自身数据进行条件判断。因此大部分 DBMS 在自连接处理了优化
mysql 创建表没指明 charset 就用数据库的charset。数据库是可以charset的哦(charset 是 character set 的简写)
mysql 创建表有两种方式
1 | -- 一个一个创建 |
DDL,DML,DCL,TCL
DDL:Data Definition Language (DDL)数据库定义语句
用来创建数据库中的表、索引、视图、存储过程、触发器等
CREATE,ALTER,DROP,TRUNCATE,COMMENT,RENAMEDML:Data Manipulation Language (DML)数据操纵语句
用来查询、添加、更新、删除等
SELECT,INSERT,UPDATE,DELETE,MERGE,CALL,EXPLAIN PLAN,LOCK TABLEDCL:Data Control Language (DCL)数据控制语句
用于授权/撤销数据库及其字段的权限
GRANT,REVOKE。TCL:Transaction Control Language (TCL)事务控制语句
用于控制事务
COMMIT,ROLLBACK,SAVEPOINT,SET TRANSACTION
DROP 表结构和表数据都会删除,释放表空间
TRUNCATE 只会清空表数据,但是保留表结构
TRANCATE 是DDL语句,DDL语句是没有ROLLBACK指令的,
ROLLBACK 只可以回滚到上一次的提交。仅仅是上一次次。DDL 没有ROLLBACK指令,你可以理解为DDL会自带一个commit,他执行完后会立刻马上会自动提交,所以你下面的ROLLBACK就到他下面的commit就打止了。
TRUNCATE 和 DELETE FROM 异同点
- 相同:
- 都可以实现对数据的删除,同时保留表结构
- 不同:
- DELETE FROM 是DML,TRUNCATE是DDL
- TRUNCATE TABLE 不能回滚!!!
- 注意:COMMIT 在DML中是默认开启的,即set autocommit=true,这是默认开启的,所以delete默认也不能回滚,只能设置为false才能回滚。
- 但是TRUNCATE不会触发TRIGGER(日志记录)所以是个危险操作尽量不用,虽然效率高。
MySQL 8.0 有DDL的原子性,但是5.7没有。即:
1 | -- mysql8.0 |
MyBatis 用${}的情况,用到表名做参数的时候就用这个。
INSERT 添加可以添加查询结果:
- 但是要注意添加的字段要和查询的字段对应。
- 字段的范围也要对应,对应或者大于。如果里面的数据没有那么长,那可以。但是最好还是大于等于。
1 | INSERT into emp(id,name) |
UPDATE 要接条件,不然会更新整个表,DELETE FROM TABLE 也是,要注意了。
小数类型建议为DECIMAL,如果字段为非负数,建议为UNSIGNED
CHAR 是固定长度的,VARCHAR 是可变长度的。超过varchar最大值,用TEXT,但是TEXT 很大,所以建议独立一张表出来
约束
- not null
- unique
- check 5.7没有,8.0有,
1 | create table test01( |
- DEFAULT
行级约束,表级约束
1 | create table test1( |
UNIQUE 可以有null,但是可以有多个null,
mysql 可以对表指定不同的存储引擎,你可以在show create table XXX 看到后面,engin=XXX;外键约束不能跨引擎,btw,基本不用外键约束。在代码应用层解决
UTF8mb4和UTF8mb3
- utf8mb3:1~3个字节表示字符
- utf8mb4:1~4个字节表示字符
mysql utf8 默认是utf8mb3。utf8mb4用于emoji表情一般;
SQL执行顺序
- SQL语句->查询缓存->解析器->优化器->执行器->找存储引擎API看用的哪个engine
InnoDB 的好处
- 你可以
show engines看到,支持事物和分布式
MyISAM 和 InnoDB
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 外键 | No | Yes |
| 事物 | No | Yes |
| 行表锁 | 表锁,即使操作一条记录会锁住整个表,不适合高并发 | 行锁 |
| 缓存 | 只缓存索引,不缓存真实数据,增加查询很多优选选 | 缓存和数据都是真实数据,都是 .idb 结尾的文件,使用的时候会更占据内存 , |
| 关注点 | 性能:节省资源,消耗少,简单业务 | 事物:并发写,事物,更大资源 |
| 默认安装 | Yes | Yes |
| 默认使用 | No(MySQL 5.5 之前 Yes) | Yes |
| 选择 | 增加查询多用MyISAM | 更新删除多优选选InnoDB |