面试总结
Java 内存分区
图解(点击展开)
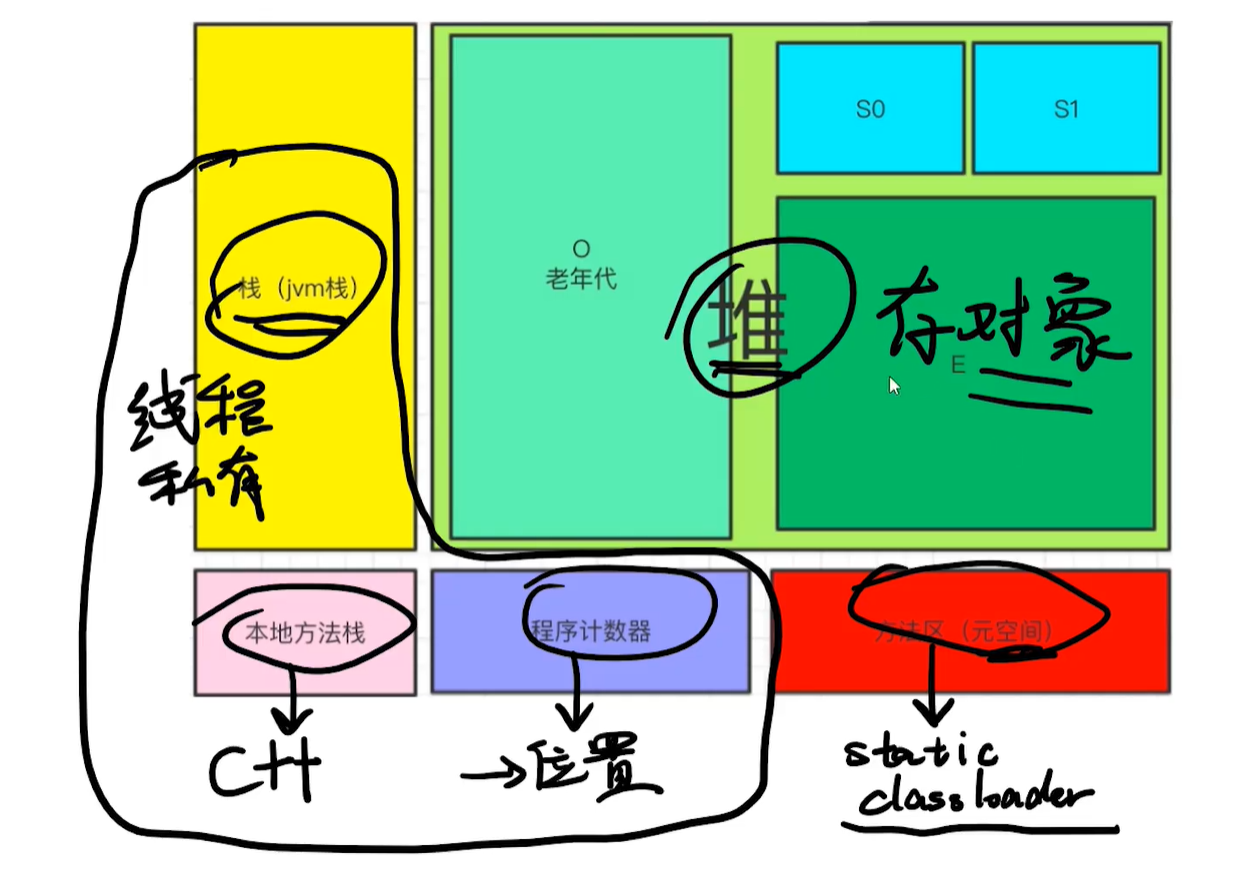
JVM 分区
根据上一个问题得,堆区是用来存放创建对象的地方,堆区的清理需要 JVM 的垃圾收集器清理。
- GCRoot– 栈 / 本地方法栈 / 方法区域
- 被 GCRoot 直接或者间接引用的对象是不能被删除的
- 孤立存在的对象,没有和 GCRoot 有直接的关系。这些对象可以被删除
垃圾回收算法
- 标记清理 – 标记存活的对象,清理未被标记的对象
- 缺点:会产生内存碎片,如果你删除了两个连续的 1KB 的对象。来一个 2KB 的对象放不下那个地方,所以会有内存碎片。
- 标记整理 – 在上面基础上把清理之后。后面的对象补上来,紧凑。
- 缺点:代价大,所有对象会前移,补空缺的内存碎片。
- 复制算法 – 将整个内存一分为二,不需要删除的复制到另一边。
- 缺点:需要内存空间大。
JVM 分区
young 区 – 也叫新生代
- 内部又分为 Eden 区域,作为对象初始分配的区域还有两个 Survivor(也叫幸存区),有时候也叫 from、to 区域,被用来放置从 young GC(也叫 Minor GC ,Eden 区满了就会触发) 中保留下来的对象。young GC 采用的是复制算法。
每一次 young GC 后,对象的年龄就会加一,然后超过 6 次。就会到 old 区 , 然后大的对象 (Integer.maxValue) 也会直接存到 old 区,因为前面不容易啊!
old 区 – 也叫老年代
- 标记清理和标记整理主要用于 old GC .
- old GC 一般会同时伴随 young GC. 称为 Full GC.
- Full GC 会引起 Java 程序暂停,应该尽量减少次数。
Permanent 区 – 永久代?
- 永久代在 JDK 7 中逐渐变化,到 JDK 8 之后完全消失,合并到了 Native 堆中
Java 中的 ==, equals 与 hashCode 的区别与联系
equals()
一般把常量写 前面 即 “常量”.equals() 防止空指针异常
- 初衷:就是判断两个对象的 content 是否相同。
Objects 类:
2
3
return (this == obj);
}
Objects 的意思是判断两个对象是否相同
很显然,在 Object 类中,equals 方法是用来比较两个对象的引用是否相等,即是否指向同一个对象。
但是我们知道:
2
3
String str2 = new String("hello");// 这里指向不同的 hello 却是 true
System.out.println(str1.equals(str2));//ture这是因为 String 重写了 equals() 方法:
String 类:(重写了 equals 方法) 不需要看懂
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public boolean equals(Object anObject) {
if (this == anObject) {// 先比较引用类型是否相同(即是佛为同一对象)
return true;
}
if (anObject instanceof String) {// 在判断类型是否一致
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])// 最后比较内容是否一致
return false;
i++;
}
return true;
}
}
return false;
}Java 中所有内置的类的 equals 方法的实现步骤均是如此,特别是诸如 Integer,Double 等包装器类。
- 一般分为三个步骤:
- 先比较引用类型是否相同(即是佛为同一对象)
- 在判断类型是否一致
- 最后比较内容是否一致
判断数组是不是对象
1 | public static void main(String[] args) { |
关于 toString() 方法
Object 类:
2
3
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}这样比较 hashCode() 没有意义。因为我们要的是比较里面的 String 或者说是实质性的东西
String 类:
2
3
return this;
}String 类重写了 toString 方法
数组类:
int[] ints =new int[10]
char[] chars=new char[10]
2
3
4
5
6
7
System.out.println(chars);//abcdefg
// 这是字符数组的特性
// 可以理解为指向的第一个数组的地址
int[] ints = {1, 2, 3, 4, 5, 6, 7};
System.out.println(ints);// 这样就不行了,没有重写 toString 方法数组类没有重写 toString( ) chars 数组可以打印是因为 chars 指向第一个数组的地址
包装类
Integer 的两种构造方法:
Constructor and Description Integer(int value)构造一个新分配的Integer对象,该对象表示指定的int值。Integer(String s)构造一个新分配Integer对象,表示int由指示值String参数。
Integer 在给 -128 到 127 用高效的效果 相同的数据存一次
但是在其他范围内存的是两个对象 (只要 Integer 有这个高效)
1 | Integer i=1; |
private static void integerTest2() { Integer i1 = Integer.valueOf((int)666); Integer i2 = Integer.valueOf((int)666); Integer i3 = new Integer((int) 666); Integer i4 = new Integer((int) 666); System.out.println(i1==i2);//false System.out.println(i3==i4);//false } private static void integerTestEqual() { Integer i1 = Integer.valueOf((int)6); Integer i2 = Integer.valueOf((int)6); Integer i3 = new Integer((int) 6); Integer i4 = new Integer((int) 6); System.out.println(i1==i2);//true System.out.println(i3==i4);//false } public static void integerTest() { Integer i1= 6; Integer i2 = 6; Integer i3 = new Integer(6); Integer i4 = new Integer(6); System.out.println(i1 == i2);//true System.out.println(i3 == i4);//false } public static void main(String[] args) { integerTest(); integerTest2(); System.out.println("=========|"); // 为什么会输出 true false // 下面的是反编译,这是 integerTestEqual(); // 可以看到 i1 i2 以自动装箱的方式创建 //i3 i4 以构造方法的方式创建 // 那为啥会有 true 返回呢? // 因为 Integer 在 valueOf() 第一次 调用时。会创建 -128~127 直接的实例 // 加到缓存,后续调用 valueOf 方法时,会返回缓存中的实例。 // 所以指向同一内存地址 为 true. // 所以 integerTest2 超过了 127 的最大值。你自己可以进 valueOf 方法里看。 }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
### String
重写了 equals 方法和 toString 方法
sout 默认打印的是他的 toString 方法
---
String =" " 和 String str=new String(" ") 的区别 ==>[StringTest.java](https://github.com/notfornothing/JavaSE/blob/main/JavaSE_Basic_Basic/src/cn/leijiba/day11/StringTest.java)
> [基于 == 判断的,因为 == 是比较的地址值.](https://blog.csdn.net/justloveyou_/article/details/52464440)
```java
public static void main(String[] args) {
/** String="" 和 String s=new String("string") 的区别*/
String str1 = "abcd";
String str2 = "abcd";
System.out.println(str1==str2);//true
// 因为 String str1 = "abcd"的实现过程:
// 首先栈区创建 str 引用,然后在 String 池(独立于栈和堆而存在,存储不可变量)
// 中寻找其指向的内容为"abcd"的对象,如果 String 池中没有,则创建一个,
// 然后 str 指向 String 池中的对象,如果有,则直接将 str1 指向"abcd"";
// 如果后来又定义了字符串变量 str2 = "abcd",
// 则直接将 str2 引用指向 String 池中已经存在的"abcd",不再重新创建对象;
System.out.println("============");
str1 = "abc";
String str3 = "abc";
System.out.println(str1 == str3);//true
// 当 str1 进行了赋值(str1="abc"),则 str1 将不再指向"abcd",
// 而是重新指 String 池中的"abc",此时如果定义 String str3 = "abc",
// 进行 str1 == str3 操作,返回值为 true,因为他们的值一样,地址一样
System.out.println("============");
str1 = str3 + "d";
System.out.println(str2 == str1);//false
System.out.println(str2.equals(str1));//true
// 内容为"abc"的 str1 进行了字符串的 + 连接 str1 = str1+"d";
// 此时 str1 指向的是在堆中新建的内容为"abcd"的对象,*************这是重点
// 即此时进行 str1==str2,返回值 false,因为地址不一样。但是值一样
System.out.println("=================");
System.out.println("以下是区别");
String str4 = new String("abcd");
String str5 = new String("abcd");
System.out.println(str4 == str5);//false
System.out.println(str4.equals(str5));//true
//String str4 = new String("abcd") 的实现过程:
// 直接在堆中创建对象。如果后来又有 String str5 = new String("abcd"),
// str5 不会指向之前的对象,而是重新创建一个对象并指向它,
// 所以如果此时进行 str3==str4 返回值是 false,因为两个对象的地址不一样,
// 如果是 str3.equals(str4),返回 true, 因为内容相同。
}
String 常用 API
—————– 不用记下来,有印象就行
- charAt
- concat – 拼接,但不改变原字符串
- endsWith
- startsWith
- equals
- indexOf
- lastIndexOf
- length
- toUpperCase
- toLowerCase
- split – 切割
- valueOf – int 转 String
- trim – 去掉头尾空格
- getBytes – 转成 byte[]
- subString – 截取子串 左闭右开 [)
对于 String 的这些方法:
可以用字符串常量来解释:所以他返回的值是变的
1 | "abcdefg".substring(2, 6); |
String 和 StringBuffer 和 String
目前只知道 String 拼接字符串 比其他两个很耗时间和内存
用 System.currentTimeMillis() 两个相减得到的
思考 成员变量为自定义的类型,那么 equals 是否调用该成员变量的 equals 方法呢?toString 呢?
是的,所以应该重写 equals 和 toString
其中 toString 调用的是 hashCode 的默认。所以应该重写才好
重写的 equals 调用的是基本数据类型的是用 ==. 引用数据类型调用的是 Objects.equals(a,b)
我看了一下他的实现,就是去调用 a 的 equals 方法。所以说要重写才好。免得到时候 equals 判断半天还不等于。免得踩坑
下面有关于 Objects 的 quals 方法
Stringbuffer 是线程安全的:
他是从 JDK1.0 版本就有的,他是线程安全
StringBuffer 源码有:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public synchronized int length() {
return count;
}
public synchronized int capacity() {
return value.length;
}
public synchronized void ensureCapacity(int minimumCapacity) {
if (minimumCapacity > value.length) {
expandCapacity(minimumCapacity);
}
}
Stringbuilder 不是线程安全的
- 从版本 JDK 5 开始,这个类别已经被一个等级类补充了,这个类被设计为使用一个线程 Stringbuilder 类,Stringbuilder 应该使用 Stringbuilder 类,因为它支持所有相同的操作,但它更快,因为它不执行同步。
Stringbuilder 没有 synchronized 锁 ,所以他不是线程安全的.
好像还有一个 Objects 类
主要用到的是 Objects 类的 Objects.equals
1 | public static boolean equals(Object a, Object b) { |
Spring AOP 几种通知
- 前置通知(Before):在目标方法执行之前执行。
- 后置通知(After):在目标方法执行之后执行,无论是否发生异常。
- 返回通知(AfterReturning):在目标方法成功执行之后执行。
- 异常通知(AfterThrowing):在目标方法抛出异常后执行。
- 环绕通知(Around):可以在目标方法执行前后自定义行为。
MySQL 四种特性
- 原子性(Atomicity):事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency):事务必须使数据库从一个一致性状态变到另一个一致性状态。
- 隔离性(Isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的。
- 持久性(Durability):一旦事务提交,则其所做的修改会永久保存到数据库中。
Spring 的注解
- @Component:通用的 Spring 组件。
- @Repository:用于 DAO 层,标识数据访问组件。
- @Service:用于业务逻辑层。
- @Controller:用于 Spring MVC 控制器。
- @Autowired:自动注入依赖。
- @Qualifier:与 @Autowired 一起使用,用于指定注入的 Bean。
- @Value:注入属性值。
- @Configuration:定义配置类。
- @Bean:定义 Bean。
- @Scope:定义 Bean 的作用域。
MySQL 赃读,幻读那些
Spring 的注解有哪些(注意不是 SpringBoot 的)
业务:SpringBoot 中返回一个 JSON, 和重定向应该怎么使用?
String , StringBuffer , StringBuilder 区别
SpringMVC 流程
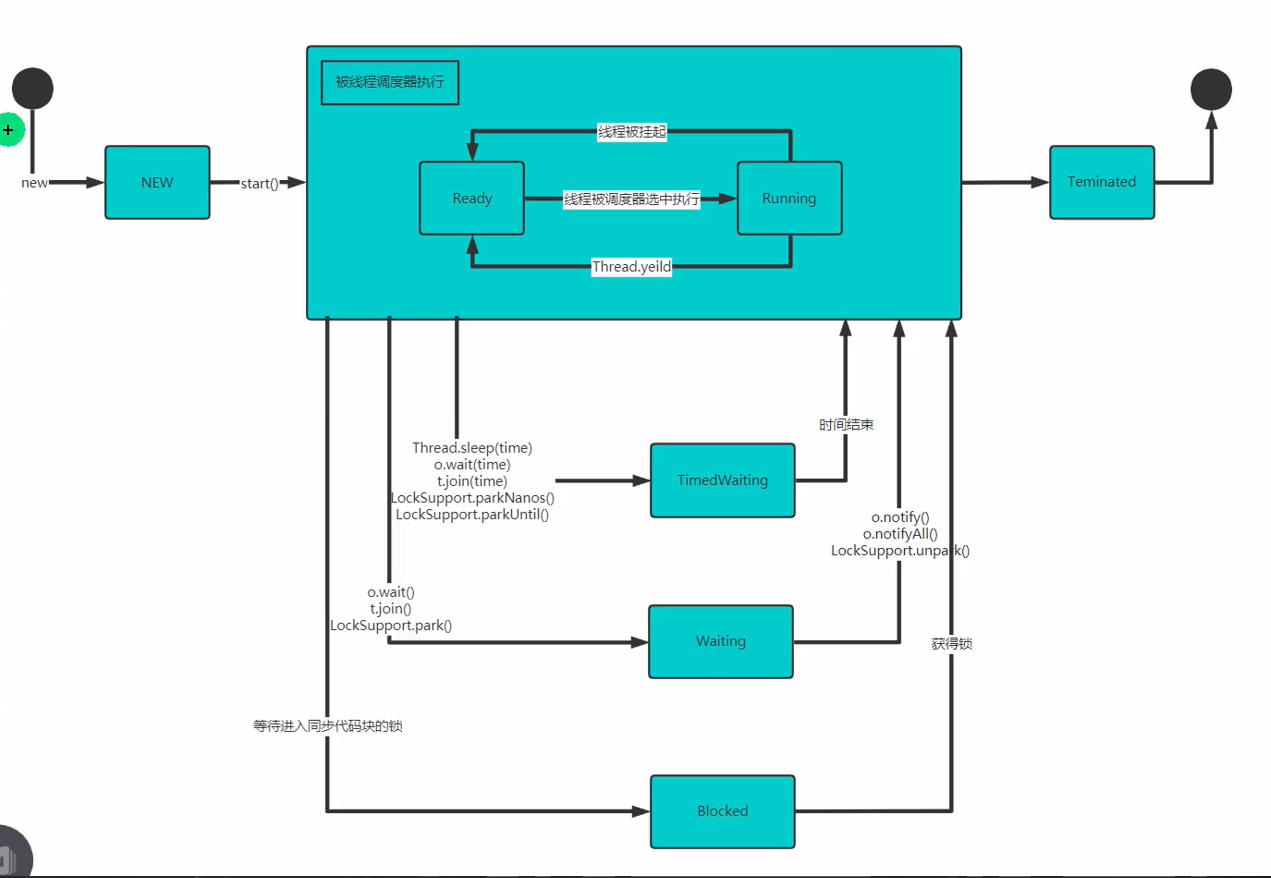
多线程状态
图解(点击展开)
hashMap 底层原理
DEBUG 代码探究其原理(点击展开)
1 | //DEBUG 代码探究其原理: |
hashMap 树化得同时满足:
- 链接长度 > 8
- 数组长度为 64
hashMap 当总元素个数 > 数组长度*0.75 会扩容 rehash(), 但是下面还有一种情况。
hashMap 当总元素没有达到
当前数组长度*0.75且数组长度 < 64时 ,有一个数组地址哈希冲突了,形成链表。在这前提下如果哈希冲突的元素达到 8,在插入第 9 个哈希冲突的元素时。数组会扩容到两倍(即长度向左移一位),而且不会形成红黑树,而是扩容 rehash(). 当第一种情况满足才会红黑树。